ALL WHICH IS WRITTEN HERE IS COMPLETE CRAP!
This post is really really old. When I wrote this I didn't know anything and I was an annoying kid who thought that he was smart. Hopefully I have grown some since I wrote this.
Spoiler: No I haven't, I still suck at everything.
This is a migrated post from my old wordpress blog. Some of the formatting may not have been properly fixed.
In this post I will introduce a little method I figured out in order to "measure complexity". I know that this method is most likely nothing new or useful by any stretch of the imagination but I had a lot of fun playing with it and trying to make it work. I came up with this method after having written a cellular automaton. The problem was that there where 2^64 different rules and some of them produced really cool and complex patterns but most where just random and boring. So I set out on the futile quest to find a way to identify these cool patterns automatically. The fact that the patterns I was trying to find was the patterns that made me go "ouu that is awesome!" when I looked at them did not really aid in finding an algorithm to find them. So essentially I was trying to find a needle in a haystack when I had no real idea of what a needle was.
This project has been an epic one filled with elation and despair (mostly despair). Although I have been aware that the measure was "decent" ever since I first tested it I have run in to so many roadblocks and I have been so wrong so many times during this project that I frequently thought about just giving up, banishing this project to the crowded folder of failed ideas.
I will not publish any code used in this post due to it being so ugly that if you where to wake up next to it after a night of heavy drinking you would spend the day crying in the shower, vowing never again to drink alcohol. But if anyone of you desperately want the code just message me and I might consider it.
Overview
With no reason what so ever I thought that the best way to start where to try to find a good measure of the "complexity " and that one way of doing that was with the following assumption/guess:
The complexity of a string is in some weird way proportional to the number of unique symbols in the run-length encoding of the string.
Okay so what do I mean by this: Lets pretend that we have the following string 10110001101. The run-length encoding of that string would then be (1,1) (1,0) (2,1) (3,0) (2,1) (1,0) (1,1) where (a,b) is to be read as a number of b's. Then we consider how many unique (a,b) tuples there are. In this case there are 4 of these. Namely : (1,1) (1,0) (2,1) (3,0). So the string 10110001101 have a complexity of 4 in my measure. One interesting to view this is is that the string 10110001101 can be expressed in a language with a alphabet consisting of only (1,1) (1,0) (2,1) (3,0). This method can obviously be generalized to strings consisting of arbitrary many symbols.
I have also done some extensive but utterly failed attempts at some theoretical explanation for using this method as a measure of complexity. I have tried several different approaches but they have all been futile. Maybe I will give it a go after having taken a course in automaton theory.
The actual implementation of this method is very straight forward but for patterns which are constructed of several strings it becomes more difficult since one has to find a way to interpret the combined. How this was to be done was not obvious but after some extensive guessing I found some methods which worked.
Application
So maybe we would like to actually try to use this method to try to find something interesting about some automatons. So lets start with the elementary automaton which we all area familiar with. So lets just go out on a limb here and say that we want to compare the patterns generated by the different elementary cellular automatons using my measure of complexity in a vain attempt to be able to identify interesting behavior of the underlying set of rules. The problem which we are faced with now is determining how to use the measure in order to compare the different patterns.
Elementary CA
In all of these examples I will use patterns that are of the size 100 * 100 cells with an initial random configuration. The initial configuration will not be considered when we do the actual comparison. Each comparison is performed 50 times and then averaged. I will only compare the 88 different unique rules.
Don't care about the actual values of the complexity score. We are only interested in comparisons between different patterns at this time.
Randall Munroe once wrote "I could never love someone who does not label their graphs" well... I say "I could never love someone who could not infer information from a context".
Rule 110 is highlighted in the plots due to it being capable of universal computation and thus embodying the essence of a "cool" pattern.
Even though only the top 20 patterns are showed each method puts the lame(class one behavior ) patterns at the bottom of the list.
Total Complexity Method
Lets start with a pretty direct approach where we just add the complexity of both the rows and the columns of the pattern. We then end up whit this list:

rank : rule : complexity
We can see that It picks out some interesting patterns for the top but otherwise there are a lot of bland and boring patterns in the top 20. The reason for this is that a pattern where all the lines/columns are very similar but have high complexity values will contribute to a higher overall value for the pattern.
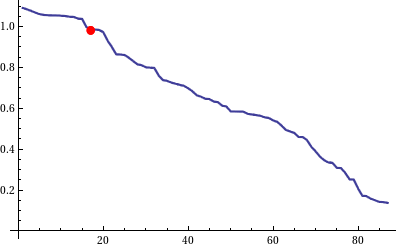
A plot of the sorted values of the complexity measures.
The red dot is rule 110
Looking at a plot of the sorted measures shows us another thing. Even though it might appear nice that the values seems to be distributed in a nice linear fashion we have no clear distinction between "cool" and "uncool patterns".
Maximum Complexity Method
In a vain attempt to avoid the pitfalls of the above method lets sum up the maximum value of the complexity of the rows and the columns. And then we get:

Legend.
rank : rule : complexity
We can see a slight improvement in the top patterns but there are still many boring patterns in the top 20. the same problem with just taking the total still appears here. So we are not there yet.
Recursive Method
Well in in a desperate attempt to avoid boring patterns where the individual lines / rows have great complexity making the way to the top. Lets try to avoid this by incorporating the complexity of the list of the complexity of each row /column to avoid patterns that have a repetitive nature. We do this as follows: Take the complexity of the string of complexity values and multiply it by the maximum value in the list of complexity values. Did anyone follow that? No probably not. But lets see what happens.

Legend.
rank : rule : complexity
Well no we start to see some nice result. Lets just note that it picks Rule 110 as the coolest rule. Which is awesome but lets be a bit skeptical still since it could just be a onetime thing and just consider the fact that it seems to group all of the interesting patterns in the top.
Another nice feature is that it seems like the lamer patterns are all also somewhat grouped together by coolness.
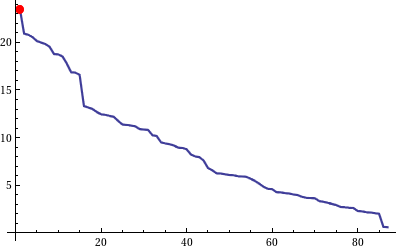
Plot of the sorted complexity measures.
The red dot shows rule 110
Well this is nice. With some vivid imagination we can see distinct jumps which seem to correlate between the coolness of the patterns.
Variance Method
Another approached that can be used in order not to have repetitive patterns getting a high score is to make use of the the variance in of the complexity of the different rows and that of the different columns. This method works in an even weirder way than the previous one and don't ask me how I came up with it since I just guessed. We get the measure M as follows:
$latex \emph{M} = (Mean( horizontal )+Mean( vertical ) )*(Variance( horizontal )*Variance( vertical ))&fg=000000$ Where Horizontal and vertical corresponds to the lists of horizontal and vertical values for the complexities.
Here we can see the results of using this method:

Legend
rank : rule : score
This method also picks out rule 110 as the top rule but then its appears to look a little bit worse since it tends to mix patterns of different "coolness" i.e rule 13 coming in at place 13 even though its a very boring rule.
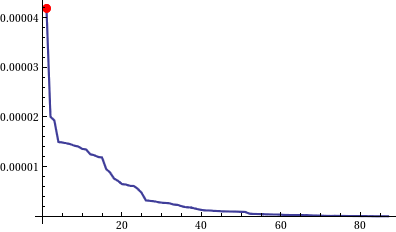 Plot of the sorted complexity measures.
Plot of the sorted complexity measures.
The red dot shows rule 110.
We can see here on this plot that the second best rule is only half as good as the best one. One question now becomes weather or not this is a good or a bad thing. Its very hard to tell in this case since the dataset is so tiny.
Look-Back/Second-Order CA
Well as of now we have seen that this method is not useless and we have some support for believing that its not complete and utter crap. But lets put it to another test! We will now apply both the Variance Method and the Recursive Method to the Look-Back Cellular Automaton.
In these simulations I have used 5362 different rules for each of the methods tested. I have then plotted the sorted values of the measures obtained through the two methods. I have also normalized the values of the measures for a clearer comparison.
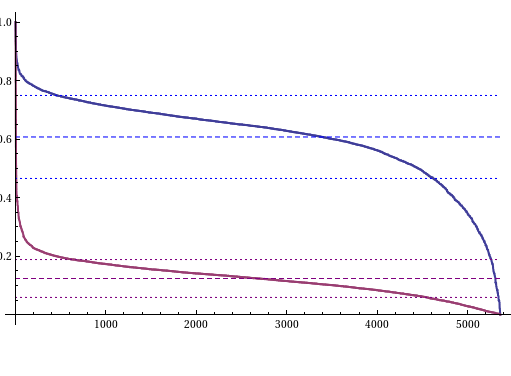 The Blue line is the distribution of the rules evaluated with the Recursive method and the Red is that of the rules evaluated with the Variance Method. The dashed line is the mean and the dotted line is the mean +- the standard deviation.
The Blue line is the distribution of the rules evaluated with the Recursive method and the Red is that of the rules evaluated with the Variance Method. The dashed line is the mean and the dotted line is the mean +- the standard deviation.
As we can see the Recursive method is way better distributed. Although on closer inspection we find that both methods have the same percentage of rules which has a score above one standard deviation from the mean. From the previous examples with elementary automatons we saw that both methods cases similar results to the same rules for the most cases. This indicates the usage of the Variance Method might be preferred since its way faster than the Recursion Method.
So lets see a few examples of some of the better rules generated by each method from the previous test.
[gallery columns=”2” type=”square” ids=”269,277,271,274,280,272,279”]
Well here we have a somewhat disappointing selection of some of the rules generated by the Variance Method. As we can see some really lame rules have jumped up to the top :/ If one continues to search through the top ranking rules one finds many many lame rules. Why this is I have no idea but its clear that the variance method is not as good which is a pain since its way faster than the Recurrence method. The loss of speed in the Recursion method might just be a problem of my implementation of the method for getting the complexity of strings of an arbitrary number of symbols.
So lets see weather or not the recursive method can perform any better.
[gallery type=”rectangular” ids=”276,278,273,275,270,281,282”]
Well well now it looks like something didn't go totally wrong. Even tough the #1 pattern might look quite lame but if one shays hmm... Scratches ones complete lack of a beard and look at it for a moment one will see that there is a actually a underlying structure so its not completely pointless. We can also see that all the others except number 500 are really really nice. Well all in all it looks like my method actually manages to find somewhat funny rules in the space of the rules for a second order cellular automaton.
Details
Don’t trust anything you see here. Its mostly crap.
Now it would be really nice to somehow normalize our measure. So that we can compare the complexity of two strings of unequal length. Why this is interesting is really not obvious since one might find it obvious that a longer string can have a greater complexity than a shorter one. It turns out that when we view complexity in this fashion the relationship between length and maximum complexity is not so obvious.
We must start by finding a way to construct the string having the highest complexity by our measure. To construct this string turns out to be very easily actually. We do this by simply following the easy pattern:1011001110001111000011111... this has the RLE: (1,1)(1,0)(2,1)(2,0)(3,1)(3,0)(4,1)(4,0)(5,1)... it is quite easy to see how this method generates the string with the highest complexity. So lets now ask another question: How long is the shortest string that have a complexity of 10 in our measure. The answer to this question is 30. Lets take a moment to consider why that is... Lets just construct that string by taking the 10 shortest possible symbols in a RLE. That in this case being: (1,1)(1,0)(2,1)(2,0)(3,1)(3,0)(4,1)(4,0)(5,1)(5,0) and this then gives us the string: 101100111000111100001111100000 which is 30 characters long.This is not the only string of length 30 with a complexity of 10 but there is no string of length 30 with a complexity greater than 10. If one writes down some more examples and then stare at them in silent contemplation for a while one finds that the minimum length of a string having a maximum complexity of C is given by the formula:
$latex l(C) = \overset{\emph{C}}{\underset{k=0}{\sum}}\frac{(k-mod(k+1,m)+1)}{m} &fg=000000$ Where m is the number of different letters in the string.
One neat thing to observer is that if we want to have a maximum complexity of 100 we would need a string of length 2550 but to have a maximum complexity of 101 we would need to have a length 2601. So how do we solve the issue of finding the maximum complexity of a string of a given length. It turns out that there is a answer on a closed form if there string only contains two different symbols.
$latex C(l) = \lfloor{\sqrt{4 l +1}-1} \rfloor &fg=000000$
But for the case of a string consisting of more than two letters one can analytically find a interval in which C is for any given l and then its just a matter of brute forcing although finding a function for C given both a length and a arbitrary number of letters seems to be very non trivial.
One major thing which I have as of yet not been able to solve satisfactory is the mean complexity of a random string. This is a very important function which would enable some nicer comparisons than one can do without a good measure for it. Although some guessing and general button mashing gives us an approximation for large lengths as roughly:
$latex \langle C_l \rangle \approx \sqrt{3} log{2} ( \frac{l}{2} ) &fg=000000$
Conclusion
Oh my God I'm so flippin tired of writing this post. I told myself that I should stop writing such long posts and here I sit with 2500 words of pure mediocreness. I doubt that anyone have bothered reading through this entire text. I'm not even sure that I would.
But enough with the self pity. Al in all this project has been a great personal successes. I have actually had an idea that kinda works. There is a lot of work that can still be done but weather or not I ever get around to that depends on the response I get here. I have learned a lot about how to structure a larger project and most of all the importance of proper and continuous testing.
Peace brothers!